Documentation for PTID
Content
Introduction
PTID is a web-based database providing association information of pesticides and corresponding potential targets from text mining. The database integrates the annotations for 1 300 pesticides classified into 22 groups, including physicochemical, toxicological, ecotoxicological and other related information. The potential targets for each pesticide in PTID were identified from literatures via the online text mining tool PloySearch. 4 000 target terms was finally mapped onto the pesticides and classified accordingly, with corresponding sequences and UniProt annotations provided.
Data source
Each data item of PTID is fully traceable and explicitly referenced to the original source.-
U.S. EPA Pesticide Programs
PTID extracted identification of pesticides information from Pesticide Chemical Search of U.S. EPA pesticide program and part of environmental fate data from Pesticide Fate Database. -
European Union (EU) Pesticide database
EU Pesticide database is made to consult the evolution of the Maximum Residue Level (MRLs) of pesticides for a product and also consult information's about active substances. -
Integrated Pest Management Centers (IPM)
Pesticide Ecological Effects Database of IPM incorporates summaries of ecological toxicity data which have been reviewed. -
Pesticide Properties Database (PPDB)
The Pesticide Properties Database (PPDB) is a comprehensive relational database of pesticide physicochemical, toxicological, ecotoxicological and other related data. The citation of PPDB as following:
PPDB (2009). The Pesticide Properties Database (PPDB) developed by the Agriculture & Environment Research Unit (AERU), University of Hertfordshire, funded by UK national sources and the EU-funded FOOTPRINT project (FP6-SSP-022704).
Lewis, K., Green, A. and Tzilivakis, J. (2007) Development of an improved pesticide properties database for risk assessment applications, EFITA/WCCA Conference Glasgow, 2007. -
NCBI PubChem
The PubChem database is designed to provide and encourage access within the scientific community to the most up to date and comprehensive source of chemical structures of small organic molecules and their biological activities. -
NCBI Gene
NCBI Gene integrates information from a wide range of species. A record may include nomenclature, Reference Sequences (RefSeqs), maps, pathways, variations, phenotypes, and links to genome-, phenotype-, and locus-specific resources worldwide. -
UniProt
The UniProt Knowledgebase is a central access point for extensive curated protein information, including function, classification, and cross-reference
Pesticide Fields
| Identification |
EPA Pesticide Chemical Search
EU Active substance database |
|---|---|
| Classification |
EU Active substance database
EPA Pesticide Chemical Search PPDB |
| Properties | Computional |
| Structure |
EU Active substance database
PubChem Generated by SMILES string |
| Environmental Fate |
PPDB
Pesticide Fate Database |
| Ecotoxicology |
PPDB
IPM EU Active substance database |
| Human Health |
PPDB
IPM |
Target Fields
| Target Terms | Text mining |
|---|---|
| Sequence |
UniProt
Gene |
| Function Annotation | UniProt |
Text mining
Target information related to pesticides were extracted by online text mining tool PolySearch(http://wishart.biology.ualberta.ca/polysearch/). Then, we assigned relevancy score as confidence score to reflect the level of significance and certainty of interactions.
First step, each relevancy score of relationship between pesticides and protein terms was generated by PolySearch (Cheng, et al., 2008). The score was enumerated by R1, R2, R3 and R4 sentences in each abstract. A R4 sentence is a sentence that contains just one of the protein terms. A R3 sentence is a sentence that contains protein terms as well as the query pesticides. A R2 sentence is a sentence that contains protein terms, one of the query pesticides, as well as at least one association word. A R1 sentence is the same as an R2 sentence but in addition, a R1 sentence has to pass PolySearch’s pattern recognition criteria. Each type of sentence presents different value, which R1 sentences are given a value of 50, R2 sentences = 25, R3 sentences = 5 and R4 sentences = 1. The relevancy score of pesticides-proteins association was the sum of the R1, R2, R3 and R4 sentences.
Next, for each protein term, the final relevance score was defined as the sum of all relevancy score of pesticides-proteins association which belongs to the current protein.
Details of relevancy score could refer to the documentation of PolySearch.
Finally, we assigned z-score for each protein term as confidence score. The z-score was defined as
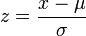
Where μ is the mean of the all the relevancy score of all protein terms and σ is the standard deviation of the relevancy score of all protein terms.
ChemMapper
In PTID, each pestcide provides ChemMapper service if the structure is suitable for similarity computation (Note: some pesticides' structure may not be suitable for similarity computation).
ChemMapper Server is a web-based open resource of chemical database searching via molecular 3D similarity calculation strategies with the help of SHAFTS, an in-house method combining the strength of molecular shape superposition and chemical feature matching.
ChemMapper support two modes for computational service, Hit Explorer and Target Navigator.
Hit Explorer mode assembled more than 300 000 000 chemical structures from public chemical vendors,
such as MayBridge, Specs, ZINC, etc. Since compounds with high structural similarity frequently exhibit similar activities,
ChemMapper service can be used to generate novel chemical scaffolds by the pattern of current structure in PTID.
On the other hand, Target Navigator mode provides a large repertoire of bioactive chemical database annotated with target information.
Users may choose target database and other parameters and submit.
The details documentation of ChemMapper could be accessed at documentation page of ChemMapper website.
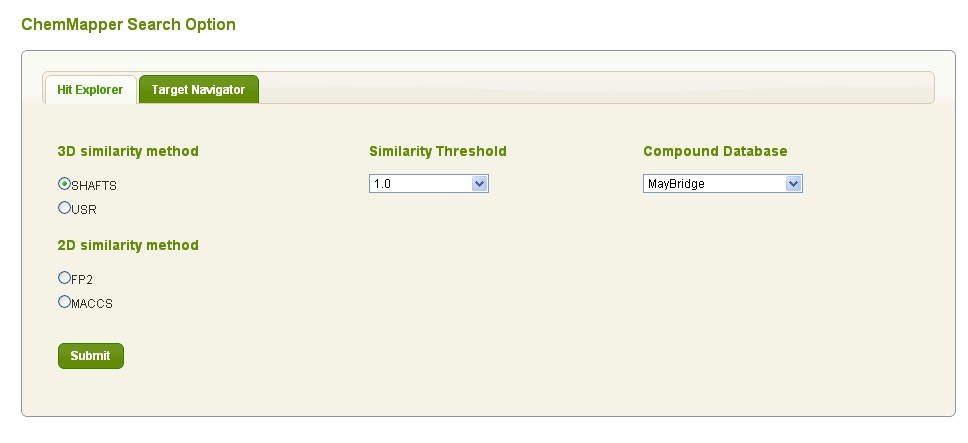
Similarity methods: According to the Similar Property Principle, two molecules with high 3D similarity tend to exhibit similar bioactivity profile. ChemMapper provides two types of 3D similarity methods:
- SHAFTS. SHAFTS adopts hybrid similarity metric of molecular shape and colored (labeled) chemistry groups by pharmacophore features for 3D similarity calculation and ranking, which is designed to integrated the strength of both pharmacophore matching and volumetric overlay approaches. The 3D superposition poses between the query and hit compounds can be visualized.
- USR. USR is based on moments of distance distributions of the molecules and recognize 3D molecular shape in ultrafast way, which circumvents the molecular alignment and comparison.
Similarity threshold: The 3D similarity score between the query and hit compounds are calculated and scaled to [0, 1]. The closer to 1.0 is the score, the higher potential of bioactivity is there between the molecules. To limit the output size, only four thresholds are set and all the compounds below the thresholds are not shown.
Database: ChemMapper collected the chemical structures and corresponding bioactivity annotations from diverse source databases. The users are free to select single or multiple databases for data accessing by toggle on the corresponding checkboxes.
Pesticides-Targets network visualization
PTID presented current entry in context of an interactive graphic network implemented by customized Cytoscape web network visualization components of interaction partners.
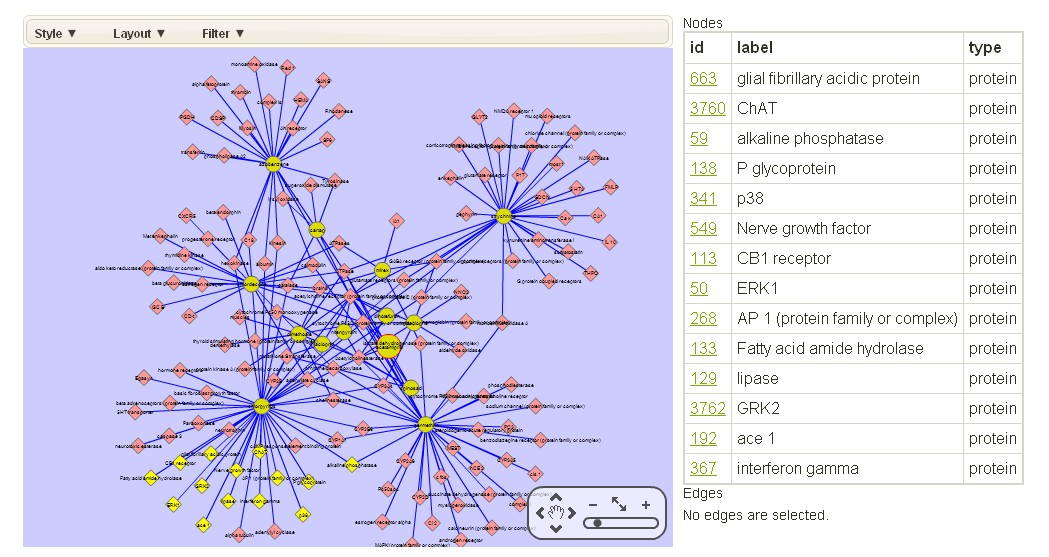
Users could see "Pesticides-Target Interaction network" button at the bottom of each pesticides and target terms pages, if the current entry has at least one high confidence relationship.

The customized Cytoscape web plugin has a user-friendly graphical user interface and supplies various tools and layouts for network analysis. Users may filter nodes or edges according to confidence score or distance between other nodes and current entry.